
Talegjenkjenning med Nevrale Nett
Ein av dei tinga som eit Nevralt Nett (NN) egnar seg til er talegjenkjenning. Det betyr å oversetja tale (lyd) til tekst. Som regel vil ein også bruka andre teknikkar (og det går også fint å bare bruka andre teknikkar) i tillegg, slik som den anvendelsen vi skal sjå på her.
Vi skal studera ein pakke som består av tre deler: ein såkalt preprosessor, det nevrale nettet, og ein postprosessor. Eit nevralt nett har problemer med å takla tale som rådata. Første trinn gjer derfor taledata om til eit format som passar betre som input til det nevrale nettet. Nettet gir så ut sannsynlighetene for kva slags lyd (fonem) som kom inn, og postprosessoren prøver å setta saman fonem til ord, basert på ein modell for kva slags lydar som passar best samen.
PREPROSESSOREN:
Lyd er svingningar i luft, og når vi tar opp talt språk får vi ei bølgeform som ser noko slik ut:

Figur: Slik ser lydbølgen ut for ordet "phonetician" uttalt av ein amerikansk mann.
Ei slik bølgeform er vanskelig for et nett å forstå. Men heldigvis fins det eit standardverktøy som produserer data som er mykje enklare å igjenkjenna, nemlig ein såkalt Fourieranalyse, eller det som kallast for Fast Fourier Transform (FFT).
Talelyden består av veldig mange frekvensar (tonehøgder) samtidig, og ved hjelp av FFT kan vi skilja ut dei ulike frekvensane og sjå kor mykje det er av dei forskjellige. Når vi gjer dette for mange tidsintervall kan vi setta dette samen til eit lydbilde med frekvens på den vertikale aksen og tid på den horisontale. Resultatet er eit spektrogram som kan sjå ut som dette:

Figur: Spektrogrammet av ein engelsk talar som seier "Rice University" Raud farge indikeret høg intensitet, blå lav. Signalet varte i 1,2 sek. Nedanfor er den korresponderande lydbølgja. Vi ser at vokalane produserer spekter med mykje energi i det lavfrekvente, mens s-lydane (c og s) produserer meir i det høgfrekvente.
Dette er eit mønster som nevralte nett er ganske gode på å kjenna igjen.
DET NEVRALE NETTET
Til å kjenna igjen dette mønsteret bruker vi eit Rekursivt Nevralt nett (RNN). Det betyr at dei skjulte nevronane er kobla tilbake til seg sjølv slik at det fins løkker i koblingsskjemaet. Slike nett passar til mønster med tidsavhengighet som tale.
Strukturen til nettet ser slik ut:
Denne pakken bruker data frå ein stor database (TIMIT). For å kunna trena nettet må vi vita kva som er rett svar. Derfor er dataene merka. Akkurat som bokstaven er den minste biten i eit ord, så fins det ein minste bit som vi kan skilja ut i tale. Det kallast for fonem. Og akkurat som ulike språk har ulike alfabet, fins det også ulike system for å klassifisera lydar. Vi bruker TIMIT-databasen som har 61 ulike fonemkategoriar.
TIMIT-databasen inneheld 4200 talte setningar frå 630 ulike talarar. Dette er mykje data, og nettet vårt er ganske stort. Derfor er det ein tung jobb å det trena opp, og ein kan gjerne bruka ein paralellmaskin for å rekna ut vektene.
Vi gir ikkje inn heile spektrogrammet på ein gong, men deler det opp i tidsvindu som representerer frekvensane ved eit bestemt tidspunkt. Det betyr at vi gir ei søyle (eller det vi kan kalle ein vektor) av spektrogrammet inn til det nevrale nettet om gangen. For ein gitt input-vektor får vi ut 61 verdiar som fortel nettets anslag av sannsynligheten for kvart av dei ulike fonemkategoriane. For å forenkla: hvis det bare var tre kategoriar så kan vi tenkja oss eit output som (0.3 0.2 0.5) Det betyr at nettet meiner det er 30 % sannsynlighet for at input-lyden var fonemkategori nr. 1, 20% for nr. to og 50% for nr. tre. (merk at sannsynlighetane summerer seg til 1 slik, det skal vera for ein sannsynlighetsfordeling)
POSTPROSESSOREN
Med et ideelt Nevralt Nett så hadde vi ikkje trengt nokon etterbehandling. For eit perfekt nett hadde vore 100 % sikker på kva slags fonem som lyden representerte. I praksis gir nettet altså bare sannsynligheter, og det er slett ikkje alltid at det fonemet med størst sannsynlighet er det rette. Men vi kan bruka sannsynlighetene som utgangspunkt for å finna den mest sannsynlige sekvensen av fonem. Og då havnar vi litt nærare det korrekte svaret.
For å forklara dette, så tenkjer vi oss eit forenkla tilfelle der det bare er tre kategoriar i språket vårt: nemlig e, h og l. Og vi har ein kort sekvens med fire tidsvindu. Vårt nevrale nett ville i så fall hatt tre outputnodar, og vi ville kjørt det i fire step. Svaret kan vi tegna som eit rutenett med 3x4 ruter, slik:
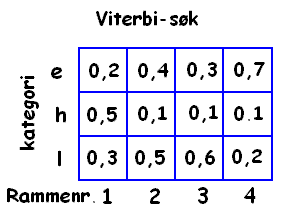
Figur: Eksempel på output frå et forenkla nett med bare tre fonemkategoriar. Når vi ser isolert på kvart tidsvindu ville vi sagt at svaret er "hlle" Men då har vi ikkje tatt hensyn til kor sannsynlig dei ulike overgangane er.
Ved å telja opp alle mulige overgangar mellom lydar frå ei lang rekkje ord i språket kan vi laga ein statistikk på kor ofte dei forskjellige overgangane opptrer. Dette kan vi oversetja til ein sannsynlighet for kvar overgang. For eksempel er overgangen h-l veldig usannsynlig, mens h-e er meir sannsynlig. Det hjelper ikkje kor sikkert nettet vårt er på at det skal vera h-l hvis denne overgangen aldri fins i språket.
På denne måten kan vi altså korrigera for mulige feil frå det nevrale nettet. For å finna ut sannsynligheten for ein bestemt sekvens, så multipliserer vi sannsynligheten for kvart fonem med sannsynligheten for dei ulike overgangane. Dette kan vi gjenta for alle mulige sekvensar, og til slutt kan vi velja den sekvensen som er mest sannsynlig.
Med tre mulige lydar og fire plassar får vi 3x3x3x3 = 81 ulike sekvenser. Og det er ikkje verre enn at vi kan rekna det ut for hånd. Men med fleire lydar og lengre setningar blir det fort uoverkommelig, sjølv for ein hurtig datamaskin. Men heldigvis behøver vi ikkje rekna ut absolutt alle, men bruka ein algoritme som heiter Viterbi Algortitmen, og den ordner denn biffen ganske kjapt.
Heller ikkje postprosessoren greier å få treffprosenten opp i hundre, men den klarer å forbetra resultatet betraktelig! Vi kan oppsummera framgangsmåten slik:
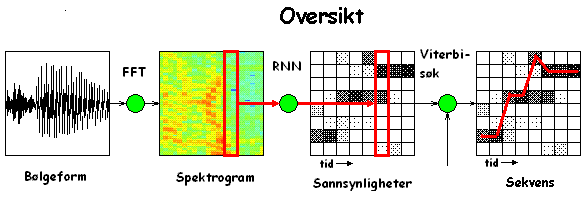
Figur: Merk at det nevrale nettet bare tar eit tidsvindu om gangen (markert med raud ramme) og produserer ein tilsvarande sannsynlighetsfordeling. Men når vi kjører nettet for alle tidsvindu i spektrogrammet får vi den totale matrisen til høgre. Her er sannsynlighetene markert som ein gråskala, med høge sannsynligheter i mørkt grå og lave i lysegrå.
Denne pakken gir gode resultat. Men ein slik hybrid-pakke er ikkje tilfredsstillande for dei som vil finna ut korleis hjernen verkeleg kjenner igjen talte ord og setningar. Det er kanskje mulig å laga både FFT og postprosessoren om til nevrale nett, slik at vi får ein fullstendig NN-pakke. Spørsmålet er om vi kjem nærare målet på den måten.