
Datamodellering med Workbench.
22 Januar 20161) Tabellar
Det første vi gjer når vi skal laga ein datamodell med Workbench, er som regel å tegna tabellane som boksar. Husk at vi no lagar ein datamodell, altså ein visuell representasjon over korleis databasen skal bli. Dei verkelege tabellane blir ikkje laga før vi gjer "Forward engineer". Meir om det seinare. Trykk på tabell-ikonet og trykk omtrent der du vil at tabellen skal vera. Då får du oppretta ein boks med navnet "table1" eller lignande. Dobbeltklikk på boksen og endre navnet til det du vil, og begynn å laga kolonner (attributtar). Den første attributten er som regel primærnøkkelen. Workbench foreslår navnet <tabellnavn>id for denne, men du kan endra det til det du vil. Denne skal som regel ha datatypen INT (heiltal) og haka av for "PK" (som står for Primary Key, dvs primærnøkkel) og "NN" som står for Not Null. Det vil sei at denne kolonnen må ha ein verdi. Hvis du i tillegg haker av for "AI" (Autoincrement) så vil MySQL automatisk legga inn ein verdi for nøkkelen ved å bruka det neste ledige talet. Dette kan vera nyttig hvis databasen ikkje skal bruka nøkkelfelt som er definert frå før, for eksempel personnummer. I såfall lar vi AI stå åpen, og legg inn data der på andre måtar. Når du har definert primærnøkkelfeltet, så fortset du med dei andre felta. Workbench foreslår både navn og datatype, men som regel vil du endra dette. Les meir om datatypar.
2) Relasjonar
Når du har laga alle dei tabellane som ikkje er reine koblingstabellar, så er det på tide å kobla disse samen ved å laga relasjonar. I menyen har du seks ulike valg når du skal laga ein relasjon. Vi skal sjå litt på disse etter tur:
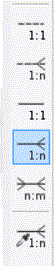
1. Ein-til-ein:
Denne relasjonstypen er neppe noke du vil ha bruk for på vårt nivå, fordi vi
godt kan klara oss uten. Men det kan tenkjast at det fins praktiske grunnar
til at det kan vera smart. La oss sei at du har ein persontabell med navn,
tlfnr og eit antall ofte etterspurte opplysningar som er kobla til ein
ekstra tabell med td. CV, historikk, bakgrunnsopplysningar og kanskje til og
med sensitive opplysningar. Hvis ekstra-tabellen er veldig stor, så kan
denne løysinga muligens gi kjappare søk på basisopplysningane. Det kan også
vera sikkerhetsmessige grunnar, td at ikkje alle skal ha tilgang til dei
ekstra opplysingane (sjøl om det kan sikrast på andre måtar) eller at ein
treng oftare backup på basisopplysningane, sidan disse blir oftare
oppdatert.
2. Ein-til-mange: Dette er den
vanligaste formen. Husk å trykkja først på mange-sida i relasjonen, og så på
ein-sida. Men hvis du trykkjer feil, kan du alltid editera relasjonen
etterpå. Her vil det automatisk bli laga
ein fremmednøkkel på mangesida som refererer til primærnøkkelen på
ein-sida.
3. Ein-til-ein: Dette er identisk
med 1, bortsett frå at det ein såkalt "Identifying
Relationship". Meir om det nedanfor.
4. Ein-til-mange: Dette er identisk
med 2, bortsett frå at det ein såkalt "Identifying
Relationship". Meir om det nedanfor.
5. Mange-til-mange:
Hvis du har laga to tabellar, og bruker dette valget, så opprettar Workbench
automatisk ein koblingstabell
mellom disse. Det er den einaste måten å realisera ein mange-til-mange
relasjon på. Merk at Workbench opprettar disse som "Identifying
Relationship", men du kan endra dette. Meir om dette også nedanfor.
6. Ein-til-mange: I staden for å la
Workbench automatisk laga fremmednøklar til relasjonen, så kan du bruka
eksisterande felt. Du kan altså sjøl definera ein felt på forhånd
og så bruka dette som fremmednøkkel til å oppretta ein relasjon. Det du då
må passa på er at du har samme datatype
(som regel INT) på fremmednøkkelen som i primærnøkkelen som den refererer
til. Fordelen med dette er at du har full kontroll på navnet, men eg ser
ikkje heilt nødvendigheten av dette valget, sidan du alltid kan endra navn
på fremmednøkkelen seinare.
2) Forskjellen mellom "Identifying" og "Non-Identifying Relationships"
Når du skal laga ein relasjon mellom to tabellar i Workbench, så har du fleire valg. Spesielt kan du velja mellom såkalte "non-identyfing" (stipla linjer) og "identifying" (heiltrukne linjer) Ka er egentlig forskjellen mellom disse?
Saken er at når du lager ein relasjon som er "identifying", så blir fremmednøkkelen på mange-sida ein del av primærnøkkelen. La oss sjå på eit enkelt eksempel vha vår sitat-database. Her har eg først laga ein versjon med "non-identyfing", og så ein versjonen med "identifying". Dette ser slik ut:
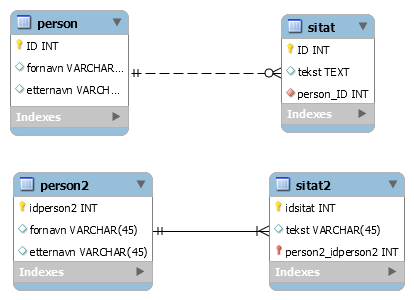
Den einaste synlige forskjellen er at den første versjonen har stipla linjer, mens den andre har heiltrukne. Men går vi inn og sjekkar definisjonane til tabellane, så oppdager vi ein liten men vesentlig forskjell:
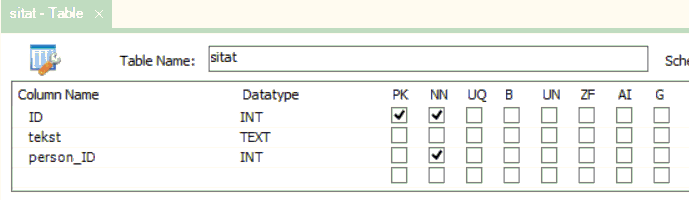
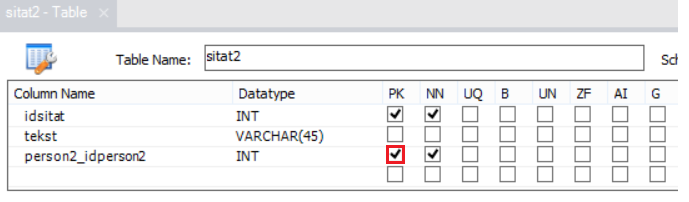
Som vi ser: den siste har haka av "PK" (som står for Primary Key, dvs primærnøkkel) for kolonnen "person2_idperson2", men den første ikkje har det. Det betyr at denne kolonnen, som er fremmednøkkel til sitat-tabellen, er ein del av nøkkelen også. Sitat2 har det vi kallar ein samansett nøkkel. For å identifisera ei rad unikt i sitat2, så treng vi begge kolonnene "idsitat" og "person2_idperson2". La oss sjå litt nærmare på dette. Her ser vi eksempel på korleis innhaldet i sitat2-tabellen kan sjå ut:
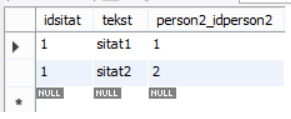
Her ser vi at "idsitat" har verdien 1 i begge radene. Dette er ikkje tillatt for eit nøkkelfelt som ikkje er samansett. For nøkkelen skal jo vera ein unik identifikator. Men her er dette feltet ikkje heile nøkkelen, men bare ein del. Heile nøkkelen består som sagt av radene "idsitat" og "person2_idperson2". Det som må vera unikt for kvar rad, er altså kombinasjonen av disse to felta. Så når første rad har 1 og 1, mens andre har 1 og 2, så går det bra. Hvis vi derimot prøver å setja inn ei rad til med 1 og 2, så vil det skjera seg.
Som nevnt ovenfor, så vil Workbench automatisk oppretta ein "Identyfing"-relasjon for ein koblingstabell når vi skal laga ein mange-til-mange relasjon. I såfall vil den ha ein samansett nøkkel beståande av to eller fleire felt. Dette er ikkje nødvendig, for du kan alltid overstyra Workbench ved å oppretta eit nytt ID-felt som har ein unik indentifikator. Dette har eg gjort i eksempelet med mange-til-mange relasjonar. Kva som er best, er avhengig av den konkrete applikasjonen.
Konklusjon: Vi vil som regel oppretta relasjonar med knappane 2 eller 5. Men ofte vil vi ha bruk for å endra på disse manuelt. Det kan du gjera ved å dobbeltklikka på koblingane og editera i det vinduet som då dukkar opp. Spesielt kan det vera aktuelt å avkryssa valget "Mandatory" på ei eller begge sidene. Det betyr i såfall at du lar minimumsbegrensningen vera 0. Dette vil du sjå på korleis relasjonen blir tegna. I første versjon av sitat-databasen over er minmumsrelasjonen 0, dvs den tillet oss å ha ein person som har ingen sitater. Dette ser vi på tegningen ved at det står ein "0" nær sitat-tabellen. I versjon 2, så er ikkje denne boksen avkryssa, og dermed er minimumsbegrensningen 1, dvs ein person må ha minst eitt sitat.
Forward engineer
Workbench har mange andre muligheter. Noken er kun visuelle, som tekst-element og bilder mens andre, som lag, er ein hjelp til å strukturer arbeidet. Men to andre har betydning for sjølve databasen, nemlig View og Rutiner. Men det skal vi ikkje ta opp her. Men det du uansett må gjera for å laga databasen når du er fornøyd med modellen, er å gjera ein såkalt "Forward engineer". Det som skjer er at då lagar Workbench ein SQL-spørring som blir sendt til MySQL-serveren. Denne består ma. av CREATE TABLE for å oppretta tabellane. Derretter får du svar tilbake om dette gjekk bra, og i såfall er du klar til å putta inn data i databasen din. I første vindu pleier vi bare å trykkja "next". I neste er det viktig å sjekka om boksen "DROP objects before each CREATE object" er huka av. I såfall vil alle tabellar bli sletta for så å bli oppretta på nytt. Då vil du mista evt. data som ligg i tabellane. Men hvis du vil bare noken av tabellane dine, kan du likevel haka av denne boksen, og så bestemma i neste vindu ka slags tabellar du vil behalda.Trykk "next", og så evt. "Show filter". Her kan du markera dei tabellane du ikkje treng å endra ved å markera dei, og trykkja ">" slik at dei dukkar opp i boksen til høgre. Trykk "next" igjen. No kan du sjå den spørringen som Workbench er i ferd med å senda. Vi vil som regel ikkje endra på den, så trykk "next" ein siste gong, og då skal databasen din forhåpentligvis vera klar.