
Databaser: ein oversikt.
1 Februar 2015Ein database er ein måte å organisera data på slik at det blir effektiv og sikkert å lagra, henta fram, endre og sletta data. Ein database består av to deler: eit program som kallast eit databasehåndteringssystem (DBMS), og sjøve databasen, dvs data. DBMSen organiserer dataene og styrer all lesing og skriving til databasen. Kommunikasjonen med databasen går via databasehåndteringssystemet, og til dette brukes et såkalt spørrespråk.
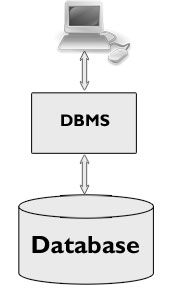 Det
finnes ulike sorter databasesystemer. Metoden ein bruker for å
organisere data kalles en datamodell. Det fins fleire typar
datamodellar. Før var mange av typen nettverksdatabase
/ hierarkisk database, mens no er det som regel relasjonsdatabaser,
som vi skal jobba med, eller såkalte objektrelasjonelle databaser som
også er basert på relasjonsmodellen.
Det
finnes ulike sorter databasesystemer. Metoden ein bruker for å
organisere data kalles en datamodell. Det fins fleire typar
datamodellar. Før var mange av typen nettverksdatabase
/ hierarkisk database, mens no er det som regel relasjonsdatabaser,
som vi skal jobba med, eller såkalte objektrelasjonelle databaser som
også er basert på relasjonsmodellen.
Les meir: Wikipedia databaser
Relasjonsdatabaser
Ein relasjonsdatabase er bygd på tabellar som er kobla saman med henvisninger, som vi kallar nøkler, mellom seg, relasjonar. Relasjoner blir brukt ma. for å hindre dobbeltlagring (redundans) av data. Vi skal sjå på et enkelt eksempel.
Anta at vi skal laga ein enkel biblioteksdatabase med oversikt over alle bøkene våre, og for kvar bok vil vi lagra opplysningar om forfattaren (kan vera alder, nasjonalitet osv). Då kan vi tenkja oss dette lagre i ein enkelt tabell slik:
| Tittel | Forfattar | Diverse |
|---|---|---|
| Markens grøde | Knut Hamsun | fekk nobelprisen i litteratur i 1920 |
| Sult | Knut Hamsun | fekk nobelprisen i litteratur i 1920 |
| Min bortekamp | Karl Ove Knausgård | skriv alt for langt, har ikkje fått nobelprisen |
| Min omkamp | Karl Ove Knausgård | skriv alt for langt, har ikkje fått nobelprisen |
| Fandens ordbok | Gunnar Øyro | artig, men lite produktiv |
Men vi ser fort at ein slik måte å lagra data på er ganske uhensiktsmessig. Vi ser at same data er lagra fleire gonger. Dette kallast dobbeltlagring eller redundans, og medfører for det første at dataene tar meir plass, og for det andre at det blir tyngre å vedlikehalda data, og større sjanse for inkonsistens. Hvis vi vil endra omtalen av herr Knausgård, så må vi gjera det for alle bøkene hans. Det er vanskeligare, og det kan fort bli feil. Derfor kan vi heller gjera det på denne måten:
Forfattar (tabell)
| FNR | Fnavn | Enavn | Diverse |
| 1 | Knut | Hamsun | fekk nobelprisen i litteratur i 1920 |
| 2 | Karl Ove | Knausgård | skriv alt for langt, har ikkje fått nobelprisen |
| 3 | Gunnar | Øyro | artig, men lite produktiv |
Bok (tabell)
| BNR | Tittel | Forfattarnr |
| 1 | Markens grøde | 1 |
| 2 | Sult | 1 |
| 3 | Min bortekamp | 2 |
| 4 | Min omkamp | 2 |
| 5 | Fandens ordbok | 3 |
Her har vi skilt ut forfattarane i ein egen tabell og kobla den til boktabellen ved hjelp av forfattarnummer. Vi seier at vi har oppretta ein relasjon mellom dei. Vi kan navngi denne relasjonen ved å sei at Forfattar har skrive bok. Relasjonen er altså "har skrive". I boktabellen har vi eit felt (dvs kolonne) Forfattarnr som unikt identifiserer ein post (rad). Dette kallast for primærnøkkel. Når vi kjenner primærnøkkelen (FNR) kan vi finna riktig forfattar. I boktabellen er feltet BNR som er primærnøkkel. Men denne tabellen har også eit felt Forfattarnr som peikar til FNR i Forfattartabellen. Vi seier at Forfattarnr er fremmednøkkel i boktabellen.
REF: Hva er en relasjonsdatabase
SQL
For å laga og bruka ein relasjonsdatabase bruker vi spørrespråket SQL som står for Structured Query Language. Det kan brukast for å
- laga, sletta og endra tabellane i seg sjøl, altså ikkje innhaldet.
- administrera brukarar og tilgangar
- setta inn, lesa, sletta og endra data
For å laga tabellane forfattar og bok kan vi bruka SQL-kommandoen CREATE. Når det er gjort må tabellane fyllast. Det kan gjerast via ein kommando som heiter INSERT. Først då er vi klare for å søkja etter data. Det kan gjerast via kommandoen SELECT. Hvis vi for eksempel vil ha ut alle forfattarar som heiter Knut til fornavn i vår lille leikedatabase, så kan vi skriva:
SELECT Enavn FROM Forfattar WHERE Fnavn = 'Knut'Forhåpentlig får vi då ut "Hamsun" som svar.
REF:
Wikipedia SQL
w3schools: SQL
Tutorial
Datamodellering
Men før vi begynner å konstruera dei tabellane vi treng i databasen er det vanlig å laga ein datamodell som viser samanhengen mellom data. Dette gjer vi vha av ER-diagram (Entitet - Relasjon). Slik kan det sjå ut for den enkle biblioteksdatabasen:
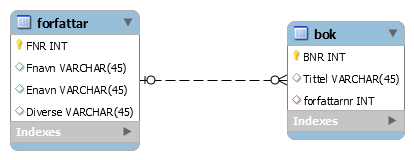
Her kan vi merka oss at vi har to entitetar (som svarar til dei to tabellane) forfattar og bok, og mellom dei har vi tegna relasjonen "har skrive". Dette er ein såkalt ein-til-mange relasjon. Vi tolkar dette som at ein forfattar kan skriva mange bøker, men ei bok har bare ein forfattar. Av og til er det ein eintydig samanheng mellom to entitetar. Då snakkar vi om ein ein-til-ein relasjon.
I eksempelet over har vi gløymt antologiane. Ein antologi er ei bok sett saman av tekstar frå fleire forfattarar. Anta at vi fekk inn følgande bok i biblioteket vårt: "Pizzasult" av Knut Hamsun & Gunnar Øyro. No har vi plutselig både bøker som har fleire forfattarar og forfattar som har fleire bøker. Dette kallar vi ein mange til mange-relasjon. Dette kunne vi tegna slik:
![]()
Merk at når vi skal realisera ein slik kobling blir vi nødt til å introdusera ein tabell imellom forfattar og bok. Meir om dette seinare.
mySQL
Det fins mange forskjellige relasjonsdatabaser som SQL Server, Access, Oracle, Sybase, DB2 og MySQL. Vi skal bruka den siste. MySQL er populært for webapplikasjonar som Wikipedia, og ein av hovedgrunnane er at dei fleste programmeringsspråk kan kobla til MySQL-databaser, som bl.a.C, C++, Java, og ikkje minst PHP, som vi skal bruka. Til dette skal vi bruka pakken WAMP (Apache, MySQL og PHP for Windows).
REF:
Wikipedia mySQL
(engelsk)
Last ned mySQL